|
不管是 Windows 电脑还是 Linux 电脑,在使用的过程中,或多或少都会留下很多重复的文件。这些文件不仅会占用我们的磁盘,还会拖累我们的系统,所以,很有必要干掉这些重复的文件。
如果你的 diff 命令没有输出,则表示两个文件相同: $ diff home.html index.html $ 但是, diff 命令的缺点是它一次只能比较两个文件,如果我们要比较多个文件,这样两个两个比较效率肯定非常低下。 2. 使用校验和 校验和命令 cksum 会根据一定的算法将文件的内容计算成一个很长的数字(如2819078353 228029)。虽然算出的结果不是绝对唯一,但是内容不相同的文件导致校验和相同的可能性跟中国男足进世界杯差不多。 $ cksum *.html 2819078353 228029 backup.html 4073570409 227985 home.html 4073570409 227985 index.html 在我们上面的操作中,我们可以看到第二个和第三个文件校验和是相同的,所以我们可以认为这两个文件是一样的。 3. 使用 find 命令 虽然 find 命令没有查找重复文件的选项,但是它却可用于按名称或类型搜索文件并运行cksum 命令。具体操作如下。 $ find . -name "*.html" -exec cksum {} \; 4073570409 227985 ./home.html 2819078353 228029 ./backup.html 4073570409 227985 ./index.html 4. 使用 fslint 命令 fslint 命令可以用来专门查找重复文件。但是这里有个注意事项,就是我们需要给它一个起始位置。如果我们需要运行大量文件,该命令可能需要相当长的时间才能完成查找。
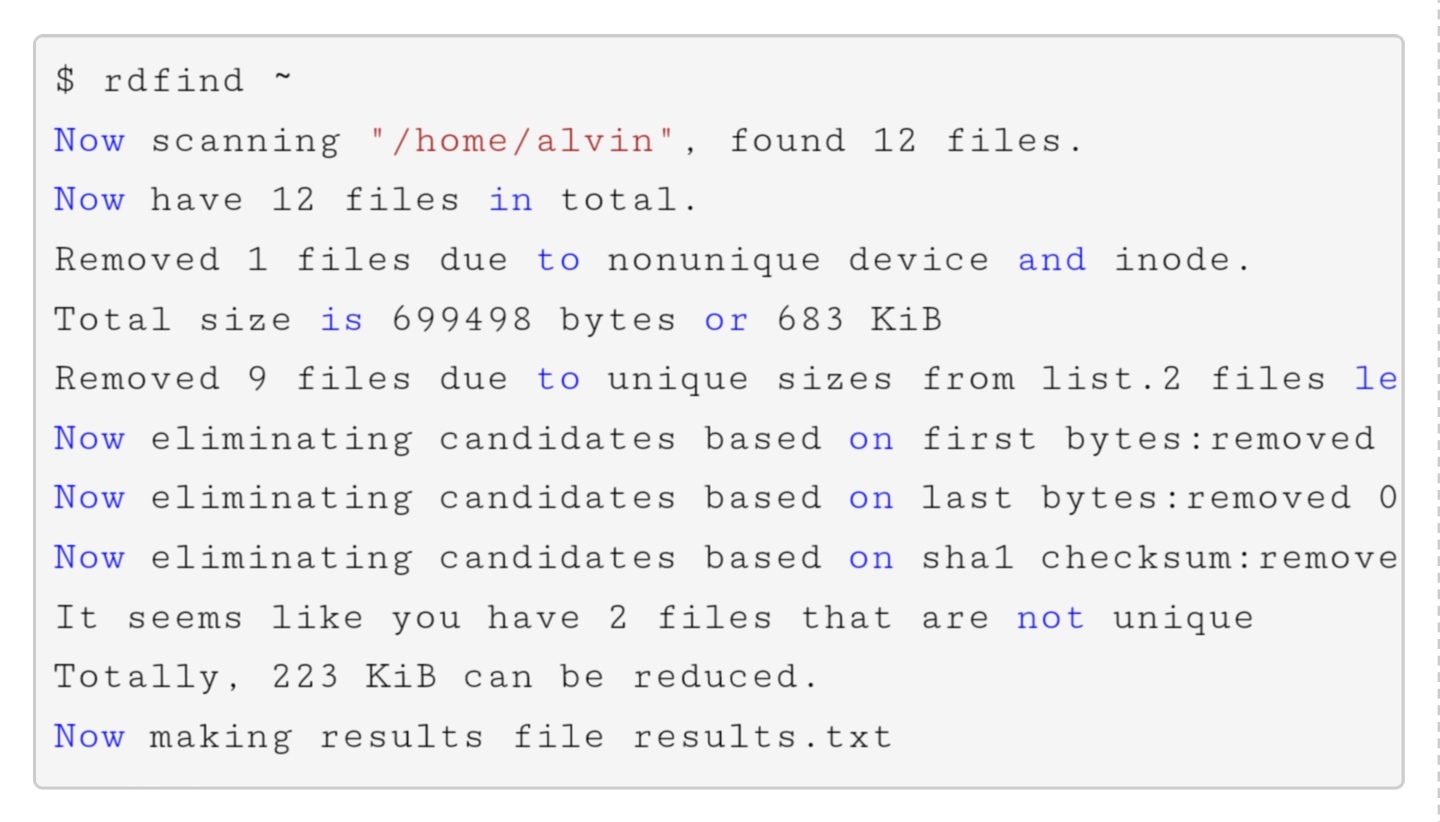
5. 使用 rdfind 命令
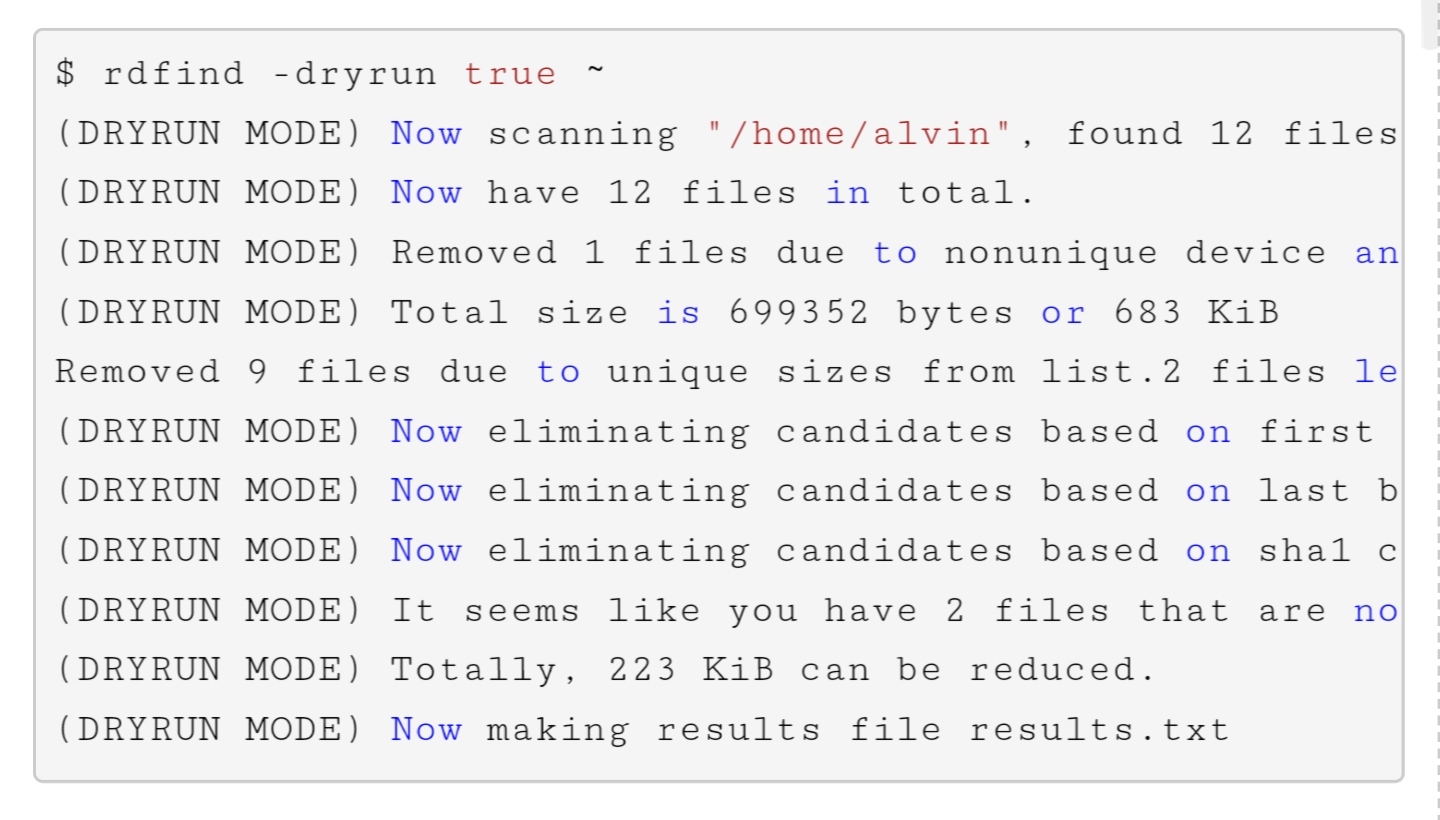
我们还可以在 dryrun 中运行。
rdfind 命令还提供一些忽略空文件(-ignoreempty)和跟随符号链接(-followsymlinks)之类的选项。下面详细解释它的常用选项。
这里需要我们注意一下,rdfind命令提供了使用 -deleteduplicates true 设置删除重复文件的选项。顾名思义,使用这个选项它将自动删重复的文件。
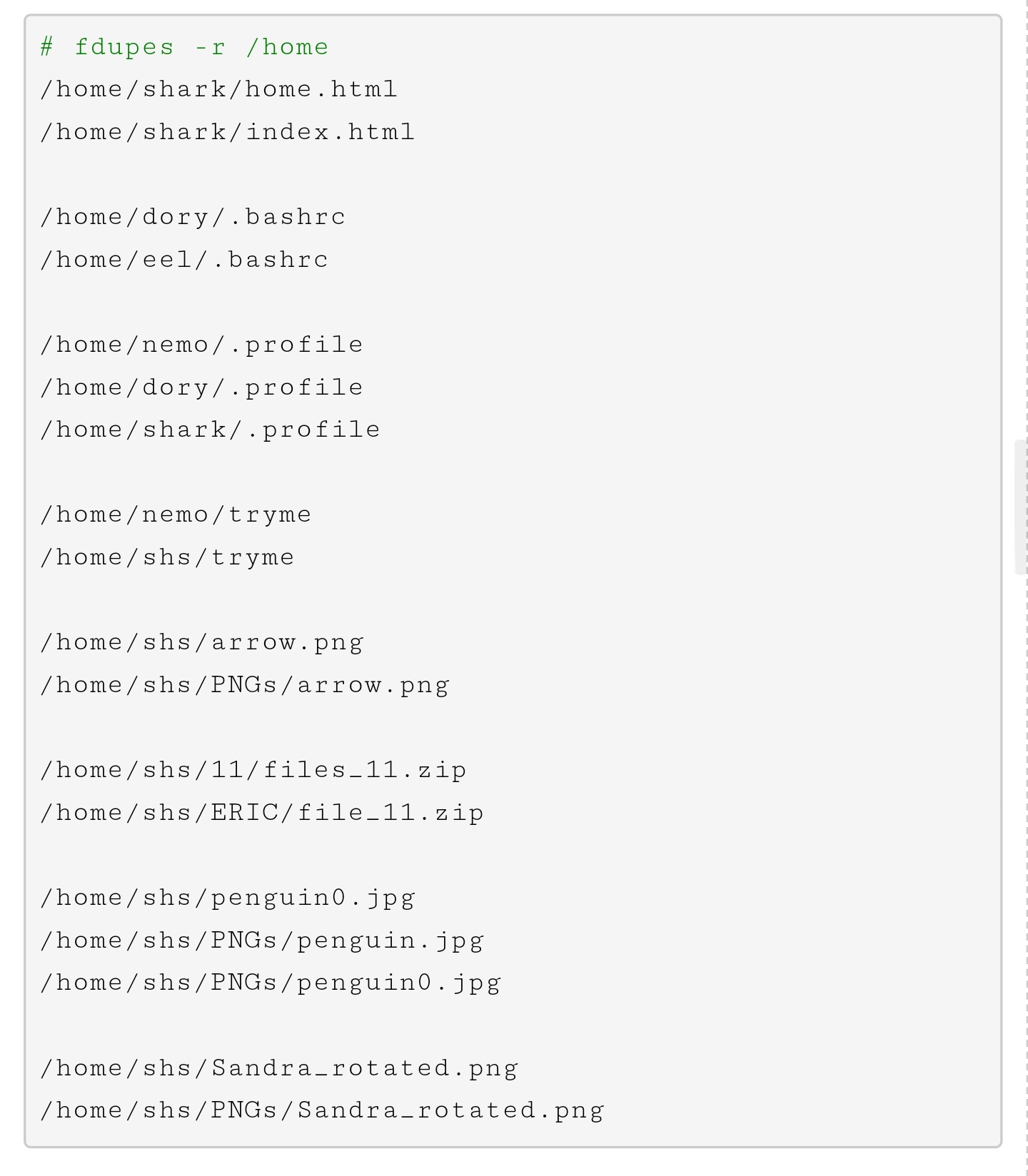
fdupes 命令的常用选项如下表所示:
小结 |
|
|
成为第一个回答人